
Towards Safer Navigation: Reward Shaping with Prior Topographic Knowledge
Project Overview
This project addresses a critical challenge in deep reinforcement learning navigation: improving agent safety while maintaining navigation capabilities. Through innovative integration of prior map information into reward shaping, we successfully enhanced the safety distance between agents and obstacles.

Research Motivation
The navigation field is dominated by two main approaches:
- Traditional Navigation Stack
- Widely deployed in real-world applications
- Modular pipeline (mapping, localization, planning, control)
- Requires extensive parameter tuning
- Limited generalization capability
- Reinforcement Learning Approach
- Primarily validated in virtual environments
- No explicit map information utilization
- Often generates unsafe navigation paths
- High collision risk with obstacles
Technical Approach
Network Architecture
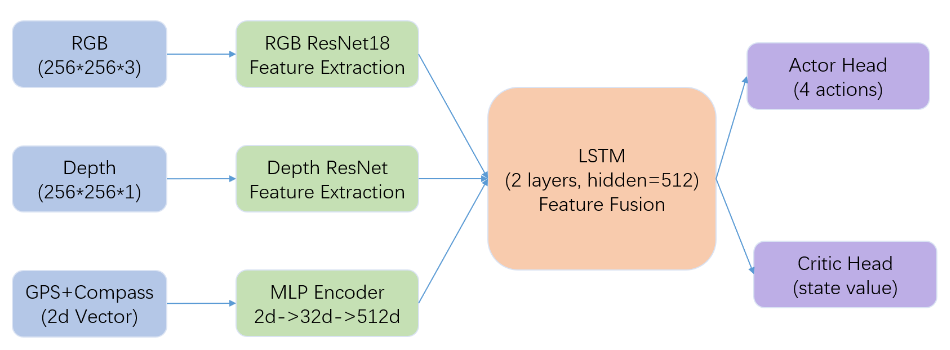
- Input Layer
- RGB images (256×256×3)
- Depth maps (256×256×1)
- GPS and compass data (2D vector)
- Feature Extraction
- RGB & Depth: Independent ResNet18 backbones
- GPS/Compass: Two-layer MLP (2→32→512)
- Feature Fusion
- Dual-layer LSTM (hidden_size=512)
- Temporal information integration
- Output Layer
- Actor Head: 4 discrete actions
- Turn left/right 30°
- Move forward 0.5m
- Stop
- Critic Head: State value estimation
- Actor Head: 4 discrete actions
Reward Shaping
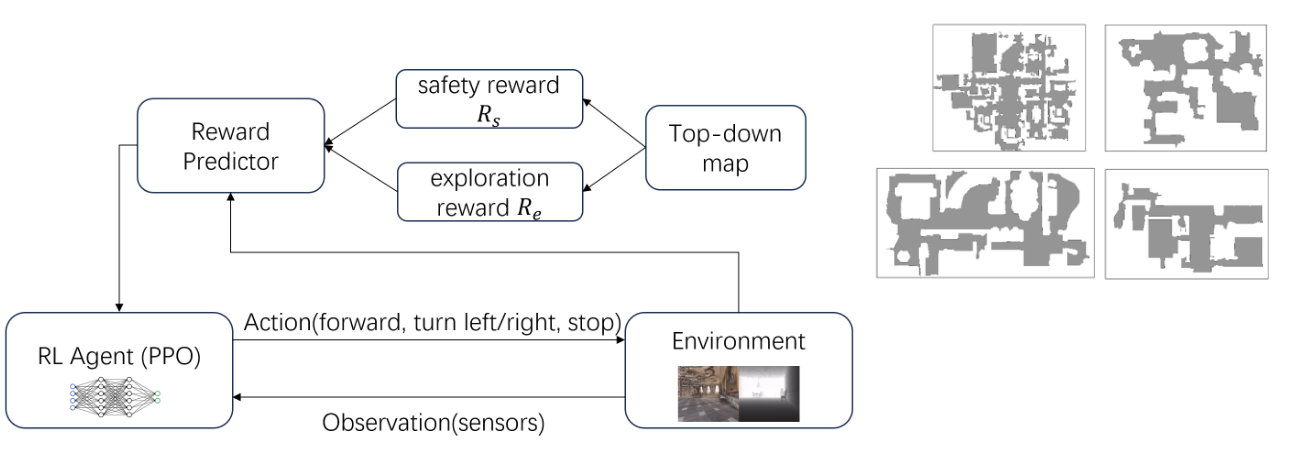
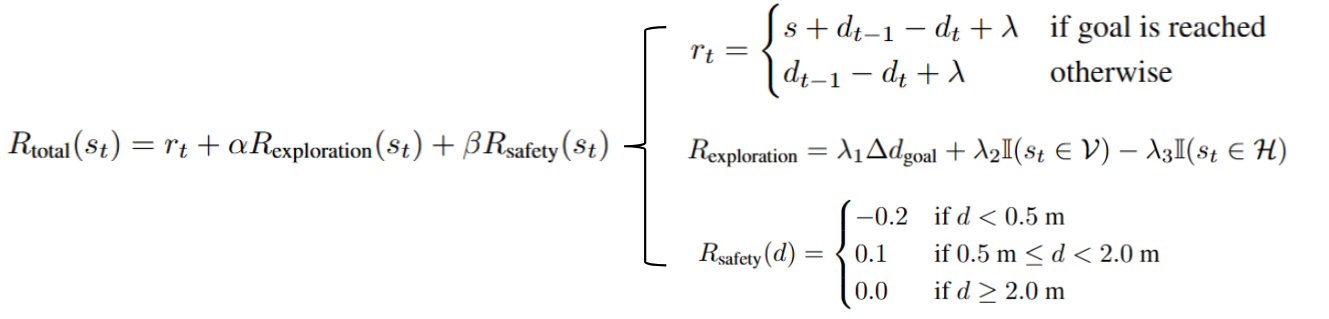
- Exploration Reward
- Encourages exploration of unknown areas
- Based on goal distance changes
- Prevents overly cautious behavior
- Safety Reward
- Based on obstacle proximity
- Negative reward for <0.5m distance
- Positive reward for 0.5-2m range
Experimental Setup
- Environment: Habitat Simulator
- Datasets: MP3D and Gibson
- Training Configuration
- 4 parallel environments
- 5 million training steps
- ~10 hours training duration
- RTX 3060 (12GB VRAM)
Evaluation Metrics
- Success Rate
- Goal reached within 500 steps
- Target threshold: 0.2m
- SPL (Success weighted by Path Length)
- Combined measure of success rate and path efficiency
- Path Safety
- Custom metric
- Average distance to nearest obstacles
Results
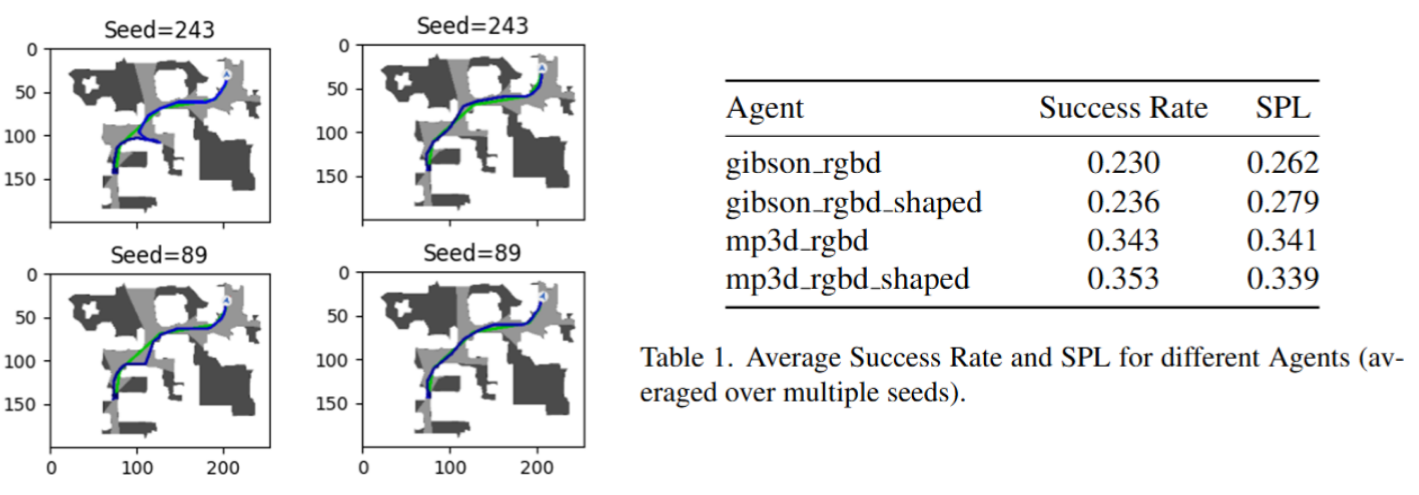
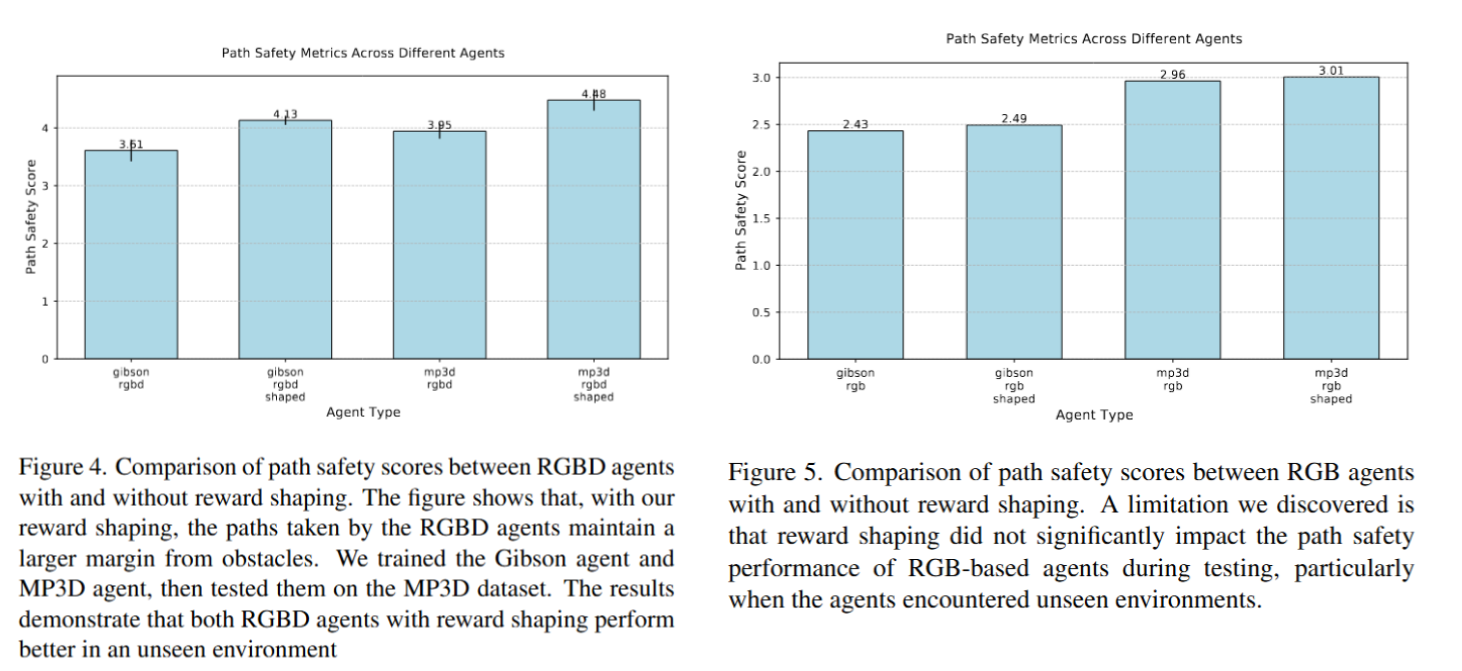
- Safety Improvements
- RGBD Agent achieved 5.75cm increase in average safety distance
- 1.64% improvement in overall path safety
- Sensor Impact Analysis
- Depth sensing crucial for safe navigation
- RGB-only input insufficient for effective safety distance mapping
Future Work
- Extend training to 75 million steps
- Optimize reward function design
- Explore additional sensor combinations
- Real robot validation
Project Member
- Jiajie Zhang (zhangjj2023@shanghaitech.edu.cn)